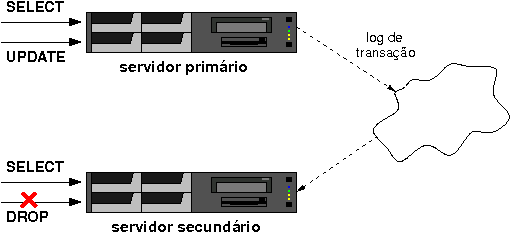
A implementação de tal cenário está descrita abaixo. Vale lembrar que os pré-requisitos apresentados no artigo anterior são utilizados aqui.
No servidor principal, editamos o arquivo /bd/primario/postgresql.conf:
listen_addresses = '*' wal_level = hot_standby max_wal_senders = 1 wal_keep_segments = 20
O parâmetro listen_addresses permite que o servidor secundário se conecte ao servidor principal para receber os logs de transação. O parâmetro wal_level indica o nível de log de transação armazenado no servidor principal; minimal (padrão) não permite que este tipo de replicação seja realizada. O parâmetro max_wal_senders indica o número máximo de servidores secundários permitidos. O parâmetro wal_keep_segments só é necessário se (i) for realizar a cópia dos arquivos com o servidor principal em atividade e (ii) se houverem paradas programadas do servidor secundário; este valor deve ser maior do que o número de arquivos de log de transação gerados durante a cópia dos arquivos. Neste caso, 20 é igual a 320 MB (20 * 16 MB).
A modificação desses parâmetros exige que o PostgreSQL do servidor principal seja reiniciado. Assim se a sua janela de manutenção não é flexível, programe-se. A aplicação dessas modificações não implica ter que iniciar a replicação imediatamente.
postgres@principal:~$ pg_ctl restart -D /bd/primario waiting for server to shut down.... done server stopped server starting
No servidor principal, crie uma role (usuário) para replicar os dados. O PostgreSQL exige que o usuário que realiza a replicação seja um super-usuário e possa se conectar ao servidor primário.
postgres@principal:~$ psql psql (9.0.1) Type "help" for help. postgres=# CREATE ROLE usuario SUPERUSER LOGIN; CREATE ROLE postgres=# \q
Dependendo da sua política de segurança, você pode precisar definir uma senha para este usuário. Neste caso, a senha deve ser informada no arquivo de senhas (~postgres/.pgpass ou %APPDATA%\postgresql\pgpass.conf no Windows) ou na string de conexão no arquivo /bd/secundario/recovery.conf.
postgres@principal:~$ psql psql (9.0.1) Type "help" for help. postgres=# \password usuario Enter new password: Enter it again: postgres=# \q
No servidor principal, edite o arquivo /bd/primario/pg_hba.conf. O método de autenticação vai depender da sua política de segurança. Se você decidiu colocar senha para o usuário que realiza a replicação, utilize o método de autenticação md5; caso contrário, utilize o método de autenticação trust.
host replication usuario 10.1.1.2/32 md5
A adição de uma nova regra de autenticação, exige a recarga das regras de autenticação.
postgres@principal:~$ pg_ctl reload -D /bd/primario server signaled
No servidor secundário, edite o arquivo /bd/secundario/postgresql.conf:
hot_standby = on
O parâmetro hot_standby indica se o servidor secundário aceita conexões.
No servidor secundário, crie o arquivo /bd/secundario/recovery.conf. Este arquivo conterá informações sobre a aplicação das modificações realizadas no servidor principal e transmitidas para o servidor secundário.
standby_mode = 'on' primary_conninfo = 'host=10.1.1.1 port=5432 user=usuario password=minhasenha' trigger_file = '/bd/secundario/failover.trg'
O parâmetro standby_mode especifica se o servidor PostgreSQL é um servidor secundário (standby). O parâmetro primary_conninfo especifica como se conectar ao servidor principal. A senha (especificado em password) pode ser omitida ali e especificada no arquivo de senhas (~postgres/.pgpass ou %APPDATA%\postgresql\pgpass.conf no Windows). Se o parâmetro trigger_file for utilizado, indica que a presença do arquivo citado (/bd/secundario/failover.trg), termina a recuperação, ou seja, o servidor passa a ser um servidor principal (que aceita quaisquer tipos de comandos; não somente aqueles comandos somente leitura).
No servidor principal, teremos que realizar a cópia física dos arquivos para o servidor secundário. Há duas maneiras de realizar esta cópia dependendo da disponibilidade do servidor principal:
- com o servidor principal parado;
- com o servidor principal em atividade.
postgres@principal:~$ pg_ctl stop -D /bd/primario waiting for server to shut down.... done server stopped postgres@principal:~$ rsync -av --exclude postgresql.conf \ --exclude pg_hba.conf --exclude pg_xlog/* --exclude pg_log/* \ /bd/primario/ postgres@10.1.1.2:/bd/secundario postgres@principal:~$ pg_ctl start -D /bd/primario server starting
Caso o servidor principal não possa parar, podemos fazer todo processo online. Neste caso precisamos executar os seguintes comandos no servidor principal:
postgres@principal:~$ psql
psql (9.0.1)
Type "help" for help.
postgres=# select pg_start_backup('replicacao', true);
pg_start_backup
-----------------
0/5044CB4
(1 row)
postgres=# \q
postgres@principal:~$ rsync -av --exclude postmaster.pid \
--exclude postgresql.conf --exclude pg_hba.conf \
--exclude backup_label --exclude pg_xlog/* --exclude pg_log/* \
/bd/primario/ postgres@10.1.1.2:/bd/secundario
postgres@principal:~$ psql
psql (9.0.1)
Type "help" for help.
postgres=# select pg_stop_backup();
NOTICE: WAL archiving is not enabled; you must ensure that all required
WAL segments are copied through other means to complete the backup
pg_stop_backup
----------------
0/90D7950
(1 row)
postgres=# \qA primeira consulta (select pg_start_backup()) prepara o servidor para iniciar a cópia dos arquivos. O próximo passo é copiar os arquivos (utilizamos o rsync mas pode ser qualquer outro aplicativo) e, neste caso, temos que excluir alguns arquivos (postmaster.pid, postgresql.conf, pg_hba.conf, backup_label, pg_xlog/* e pg_log/*). Indicamos que a cópia já foi concluída executando a função (pg_stop_backup()). Vale lembrar que o parâmetro wal_keep_segments no servidor principal deve ser maior do que o número de arquivos de log de transação gerados durante a cópia. Isto porque o servidor secundário precisará destes arquivos (eles não podem ser reciclados) para "acompanhar" o servidor principal. Caso o parâmetro wal_keep_segments não seja suficiente, (i) você terá que aumentar o valor e realizar todo este passo novamente ou (ii) caso você esteja arquivando os arquivos de log de transação basta copiá-los para o diretório pg_xlog do servidor secundário.
Neste momento você pode iniciar o servidor secundário. Não se esqueça de criar os arquivos postgresql.conf e pg_hba.conf no servidor secundário.
postgres@secundario:~$ pg_ctl start -D /bd/secundario server starting
Caso os logs estejam habilitados (logging_collector = on) no servidor secundário, as seguintes mensagens indicam que a replicação está acontecendo com sucesso:
LOG: database system was interrupted; last known up at 2010-11-14 14:08:19 BRT LOG: entering standby mode LOG: redo starts at 0/5044CB4 LOG: restartpoint starting: xlog LOG: consistent recovery state reached at 0/A000000 LOG: database system is ready to accept read only connections LOG: streaming replication successfully connected to primary
Neste momento, espera-se que o servidor secundário esteja "acompanhando" o servidor principal mas sempre em um estado consistente. Assim, a mesma consulta em ambos servidores podem retornar resultados diferentes (lembre-se que a replicação é assíncrona).
Se você tiver perguntas, as listas de discussão pgbr-geral (português) e pgsql-general (inglês) são bons lugares para perguntar.
Bom dia nem sei se este blog ainda esta ativo, mais queria deixar aqui meu agradecimento por este post foi de muita ajuda para mim. Obrigado Euler!
ReplyDeleteOlá Euler,
ReplyDeleteExcelente post. Fiquei apenas com uma dúvida: Quando eu precisar colocar o servidor secudário em produção o que devo desligar nas configurações?
Nada. Os parâmetros que não são do servidor de produção (quando ele passar a ser) serão ignorados. Para promover o servidor secundário a servidor de produção:
DeleteNa versão 9.1 ou superior execute o comando:
pg_ctl promote -D /path/to/pgdata
Na versão 9.0, você terá que configurar o parâmetro trigger_file no recovery.conf. Assim, basta criar o arquivo no local especificado no parâmetro que em alguns segundos o servidor secundário passará a ser servidor de produção.
This comment has been removed by the author.
DeleteOlá Euler,
DeleteEstou com uma dúvida parecida com a do Renato. Depois que eu promovi o slave para master, como faço para o master voltar a ser master e o slave para slave?
Existe uma maneira de promoção automática (master caiu automaticamente slave assume) ?
Grato.
Falar em transferência em caso de falha (aka failover) e volta ao cenário anterior (aka failback) em bancos de dados é complicado porque se a replicação for assíncrona, ao promover o servidor secundário a servidor principal, o servidor principal antigo poderá conter dados que não foram replicados. Neste caso a volta fica comprometida porque não é possível determinar quais os dados estavam no servidor principal antigo que devem ser descartados (ou mesmo considerados). Neste caso, não é possível voltar ao cenário anterior sem montar todo cenário de replicação (duas vezes). Supondo que o servidor A seja o principal e o servidor B seja o secundário (slave), se você realiza o failover (A -> B), para fazer a volta (B -> A) você terá que obrigatoriamente:
Delete(i) montar uma replicação com A sendo o secundário de B (é aconselhado realizar um rsync de B para A para minimizar o tempo -- já que os dados estão quase iguais);
(ii) promover o servidor A para principal (failover de B -> A);
(iii) montar uma replicação com B sendo o secundário de A (novamente é aconselhável realizar um rsync).
Quanto a promoção automática, isso deve ser feito com algum software de HA (por exemplo, heartbeat ou corosync/pacemaker).
Obrigado pela ajuda, era isso o que eu imaginava que deveria fazer.
DeleteSó mais uma dúvida, fui realizar um teste com um script onde eu criei uma sequence que realizava um auto incremento de 1 em 1.
Quando eu promovia o slave para mestre, o incremento pulou a sequencia quando começou a ser inserido pelo antigo slave.
Você sabe me dizer o por que acontece isso?
Andei pesquisando e vi que é "normal" acontecer isso na replicação.
Grato.
Isso é um detalhe de implementação. Há uma cache de valores da sequência (geralmente 32) para evitar ter que escrever a cada incremento da sequência no WAL. O efeito colateral disso é deixar um "buraco" nas suas sequências mas como sequências podem ter "buracos" não vejo problema nisso. Vide uma longa discussão sobre o assunto em [1][2].
Delete[1] http://postgresql.1045698.n5.nabble.com/Coluna-quot-log-cnt-quot-de-uma-Sequence-td2049816.html
[2] http://www.postgresql.org/message-id/27779.1249500343@sss.pgh.pa.us
Obrigado pela resposta Euler, deu pra entender o conceito.
DeleteAbraços.
Parabéns pelo artigo, como perguntado pelo colega anterior, esse bloq ainda está em atividade?
ReplyDeleteEstá mas ando meio sem tempo de revisar os textos que já estão prontos e ainda não foram publicados. :(
DeleteOla pessoal, estou tentando dar um comando no shell no postgresql (windows) e estou utilizando a seguinte sintaxe...
ReplyDeleteselect pg_start_backup('nome do meu banco de dados', true);
ele responde um registro
agora digito:
pg_basebackup -U postgres -D /var/lib/pgsql/9.4/data/db/secundario -P -h Ip do Slave -Ft
e nao acontece nada
quando dou esse comando
pg_stop_backup();
aparece a seguinte mensagem:
ERROR: syntax error at or near "ph_basebackup"
LINHA 1: pg_basebackup -U postgres -D /var/li/psql/9.4/data/db/secu...
Alguém sabe o que esta acontecendo?
desde já agradeço... Obrigado!!!
Muito bom seu tutorial.
ReplyDeleteMe tira uma duvida.
boa noite tem como configuro a replicação Streaming para ele replicar ao fim de cada transação?
Na replicação assíncrona, você não escolhe o momento de replicar. Contudo, se a replicação estiver fazendo "streaming", a transação que acabou de ser efetivada será enviada. Porém, se o servidor réplica parar por algum tempo, quando ele voltar terá que aplicar todas as transações pendentes. Nesse tempo parado, a garantia de replicar ao fim de cada transação não poderá ser cumprida (nada que um monitoramento não possa alertá-lo).
DeleteNa replicação síncrona, você tem a garantia que a transação chegará no outro servidor ANTES da efetivação da mesma no servidor principal. É um modelo que produz uma dependência entre os servidores, ou seja, se um deles parar o postgres para de efetivar transações (no assíncrono não há essa dependência). Assim, eu consigo garantir que a transação estará no servidor réplica mas você será penalizado no tempo da transação que será no mínimo o dobro da latência entre os servidores.
Obrigado pelo esclarecimento!!
DeleteÓtimo o tutorial, porem tenho uma duvida.
ReplyDeleteExiste a possibilidade de realizar essa configuração mas evitar a replicação de alguma tabela especifica ?
Não. Replicação física envia tudo. Para replicar objetos específicos você precisa de replicação lógica.
DeleteComo faz, se o servidor standby perder sincronismo, para que este retome o processo de sincronização? Sera necessario recriar tudo?
ReplyDeleteOBrigado!